

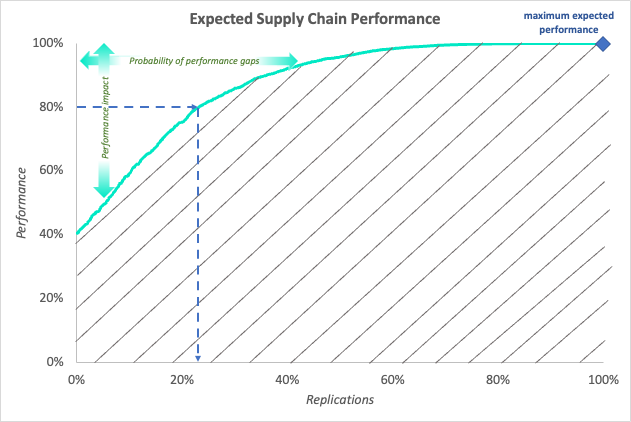

Risk mitigation in supply chain: Start with a digital twin
In recent discussions around strengthening supply chains, there’s been a significant focus on agility and resiliency. A central theme in these discussions is the concept of end-to-end visibility within...
Read more

